 ERA
ERA
Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Overview of ERA
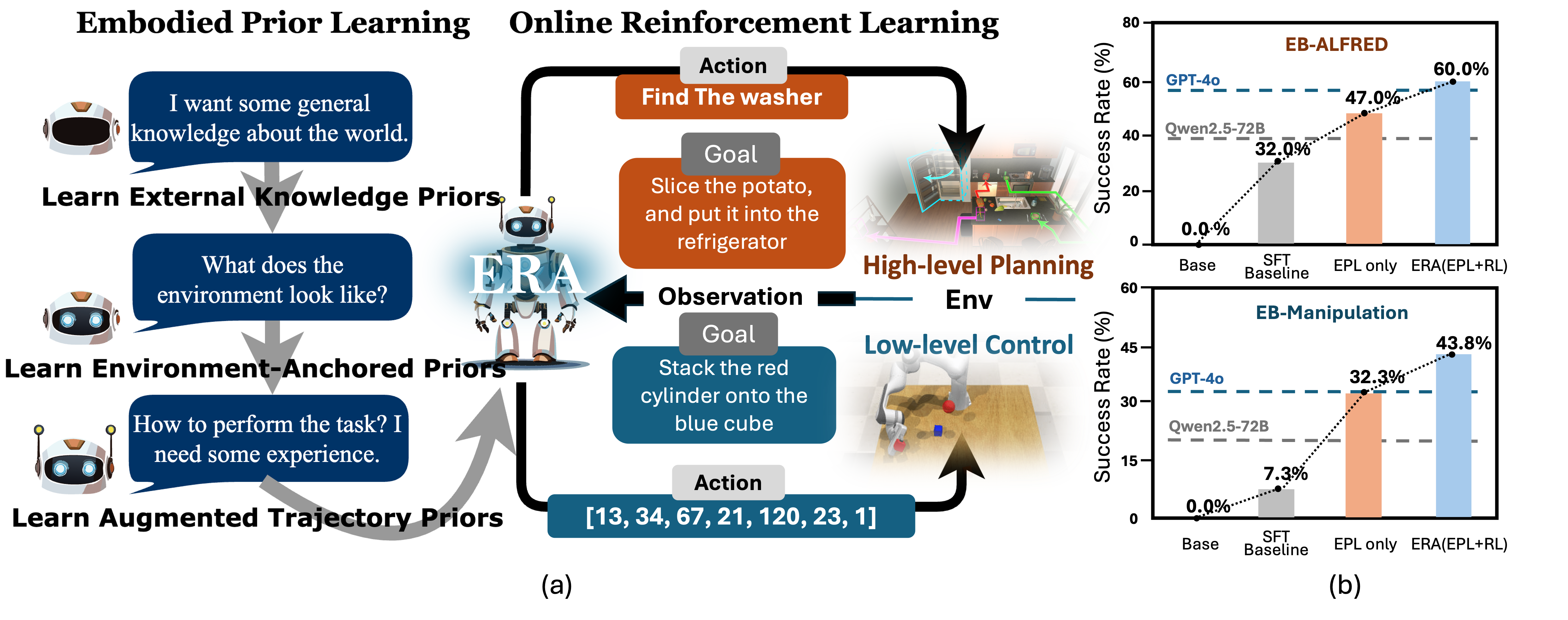
We introduce the Embodied Reasoning Agent (ERA), a framework that transforms a compact Vision Language Model (VLM) into a performant and efficient embodied agent. In this work, we study: 1. What prior knowledge does embodied agent require before RL and 2 What make RL in long-horizon embodied task stable and effective? We distill them into a unified post-training regime that is capable of delivering both high-level planning agent and low-level control agent, by different curation of training data. This comprehensive approach not only solves level-specific tasks but also paves the way for future hierarchical policies and thus, more general embodied intelligence.
ERA Framework
We build ERA with the aim of a general approach where we first 1. Infuse foundational capabilities into the model, which is categorized into three kinds of embodied prior knowledge, and then 2. refine the agent by online reinforcement learning with rich process reward and turn-level GAE.
ERA Stage-1: Embodied Prior Learning
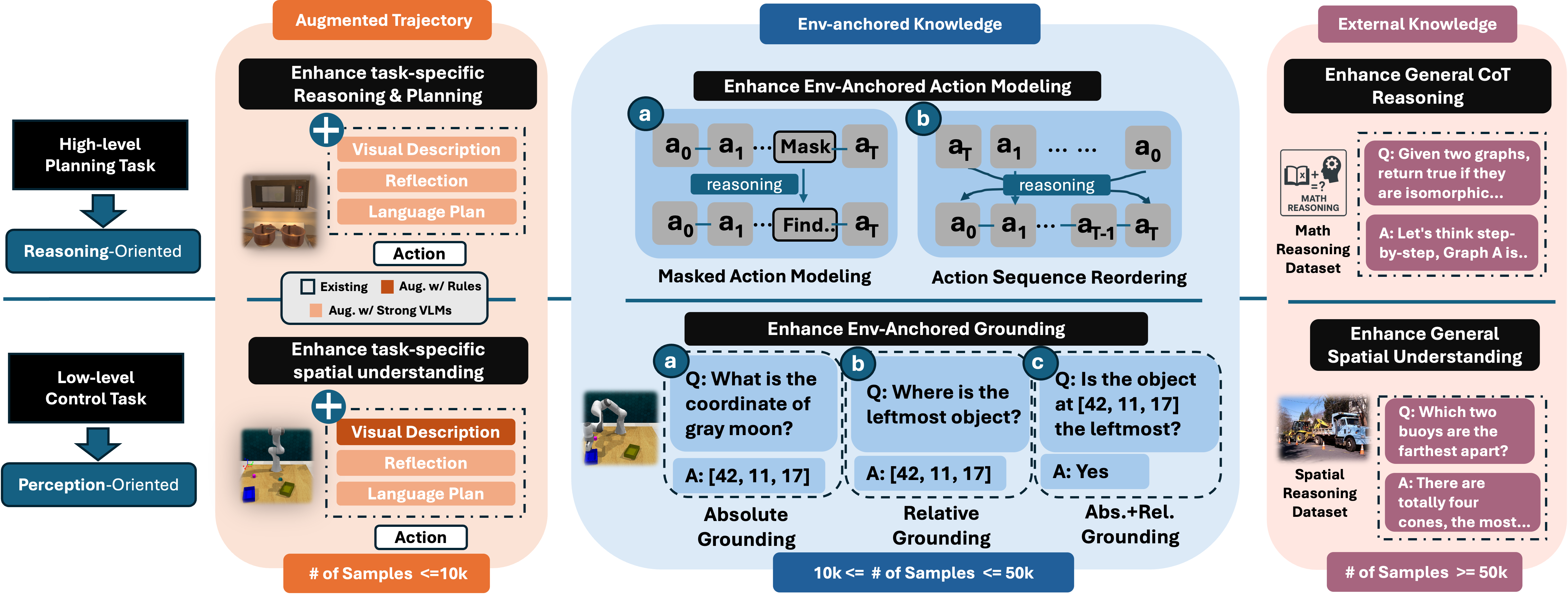
The first stage, Embodied Prior Learning, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of- environment datasets.
ERA Stage-2: Online Reinforcement Learning
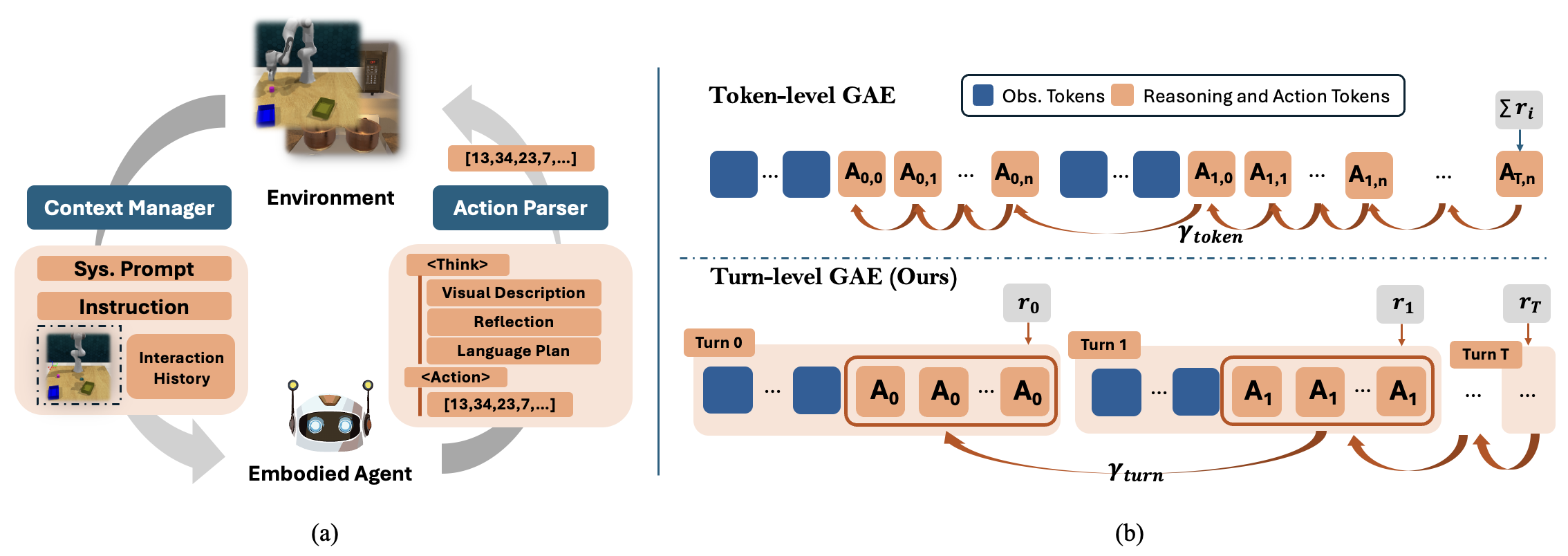
In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization.
Experiments
ERA empowers a 3B model to surpass all existing training-based models with equal or larger size, and improve upon proprietary models like GPT-4o by 8.4 and 19.4 points, respectively on high-level and low-level tasks on a comprehensive evaluation platform, EmbodiedBench. Importantly, it demonstrates strong generalization capabilities across absolutely unseen tasks(Spatial and Common-Sense).
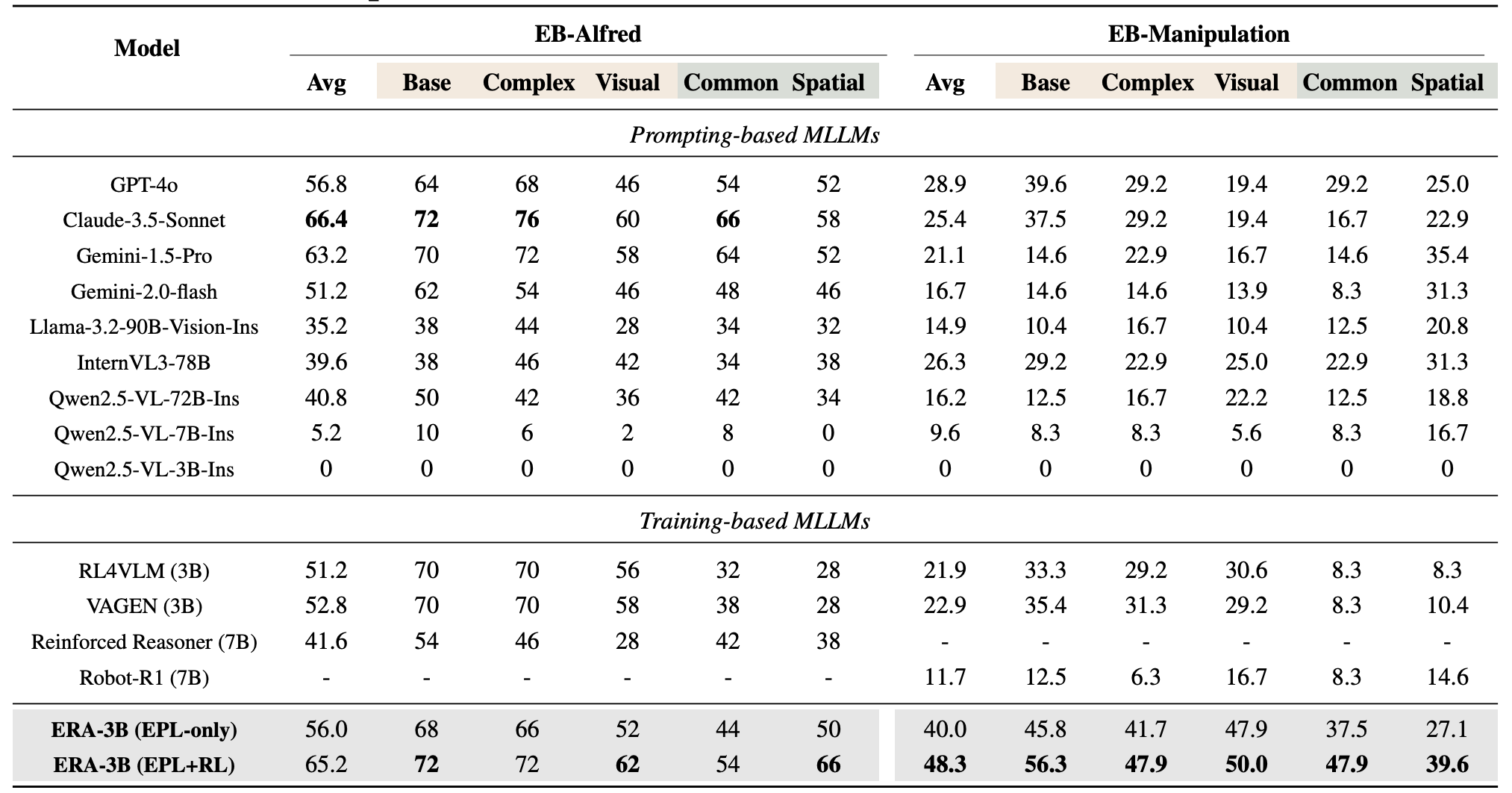
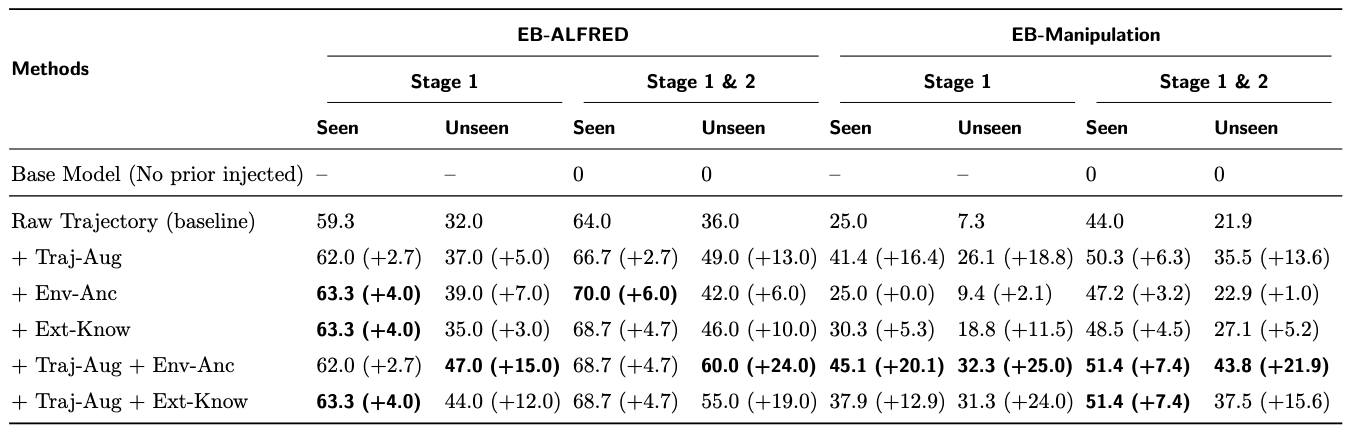
(1) Trajectory-Augmented Priors Achieve the Largest Individual Gains in Generalization.
(2) Environment-Anchored Priors Improve Seen and Unseen Tasks Equally, While External Knowledge Priors Favor Unseen Tasks.
(3) Combining Trajectory-Augmented and Environment-Anchored Priors Elicits the Best Performance.
Case Study
Below demonstrates an example: After training with ERA framework, a 3B model that originally fails on all tasks, can now perform step-by-step reasoning and actions to accomplish very challenging task: (a) on EB-ALFRED, it identifies and reflects on earlier errors to finally place a plate onto a specific spot on the table; (b) on EB-Manipulation, it accurately places the star into the correct slot of the shape sorter.

-->
BibTeX
@article{chen2025era,
title={ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning},
author={Chen, Hanyang and Zhao, Mark and Yang, Rui and Ma, Qinwei and Yang, Ke and Yao, Jiarui and Wang, Kangrui and Bai, Hao and Wang, Zhenhailong and Pan, Rui and Zhang, Mengchao and Barreiros, Jose and Onol, Aykut and Zhai, ChengXiang and Ji, Heng and Li, Manling and Zhang, Huan and Zhang, Tong},
year={2025}
}


